
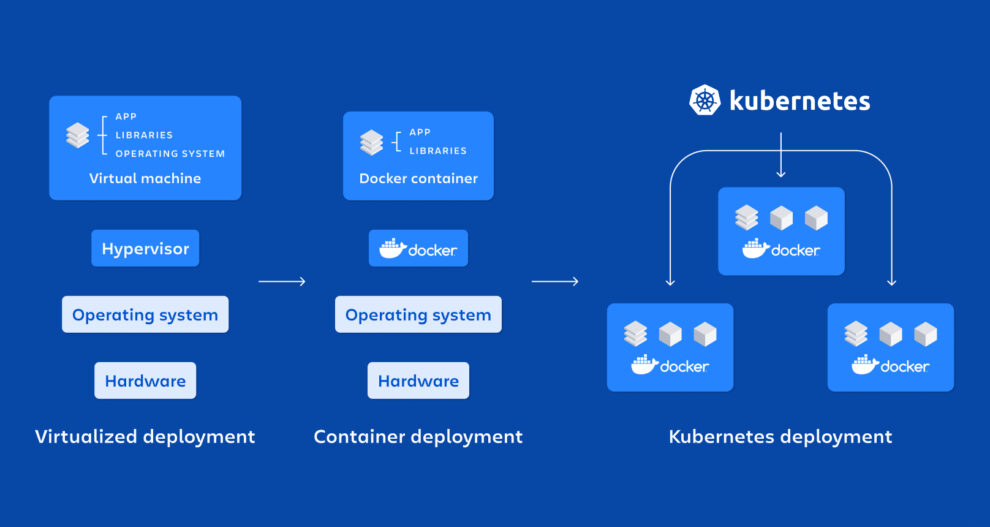
Kubernetes is an open-source container orchestration platform that automates many manual tasks required in containerized application deployment, management, and scaling.
How does Kubernetes operate?
- When developers construct a multi-container application, they lay out how all the elements will fit and operate together, how many of each component will run, and generally what will happen when obstacles (such as several people signing in at the same time) are encountered.
- They save their containerized application components in a container registry (local or remote) and record their thoughts in one or more text files, including a configuration. They “apply” the settings to Kubernetes to launch the application.
- Kubernetes’ role is to analyze, implement, and maintain this configuration unless informed otherwise. It:
- Analyses the configuration, ensuring its needs are consistent with all other application configurations operating on the system.
- Finds resources suitable for operating the new containers (for example, certain containers may require resources such as GPUs that are unavailable on all hosts).
- Grabs container images from the registry, start the new containers and assists them in connecting to one another and to system resources (e.g., persistent storage) so that the application may function as a whole.
- Then Kubernetes watches everything, and when real occurrences deviate from desired states, Kubernetes attempts to correct and adapt. If a container, for example, crashes, Kubernetes restarts it. When an underlying server dies, Kubernetes seeks resources to operate the containers that the node was hosting elsewhere. If traffic to an application unexpectedly increases, Kubernetes may scale out containers to manage the extra demand, according to the rules and restrictions specified in the configuration.
What may Kubernetes be used for?

The fundamental benefit of using Kubernetes in your environment, particularly if you are optimising app development for the cloud, is that it provides a framework for scheduling and running containers on clusters of physical or virtual computers (VMs).
In general, it enables you to fully install and rely on container-based infrastructure in production situations. And, because Kubernetes is primarily about automating operational activities, you can perform many of the same things for your containers that other application platforms or management systems allow.
Developers may also use Kubernetes patterns to construct cloud-native apps with Kubernetes as a runtime platform. Patterns are the tools required by a Kubernetes developer to create container-based apps and services.
You may use Kubernetes to:
- Containers may be orchestrated across several hosts.
- Improve your hardware utilization to maximize the resources required to operate your corporate apps.
- control and automate the deployment and updating of applications.
- To execute stateful programs, mount and add storage.
- On-the-fly scaling of containerized apps and their resources
- Declaratively manage services to ensure deployed applications always perform as you intended them to.
- With autoplacement, autorestart, autoreplication, and autoscaling, you can self-diagnose and self-heal your apps.
Kubernetes, on the other hand, is dependent on other projects to deliver these coordinated services properly. Its full potential may be realized by integrating additional open-source projects. Among these required components are (among others):
- Registry, such as the Docker Registry.
- Networking, such as OpenvSwitch and intelligent edge routing.
- Kibana, Hawkular, and Elastic are examples of projects that use telemetry.
- Security is provided through projects such as LDAP, SELinux, RBAC, and OAuth with multitenancy layers.
- Automation, with Ansible playbooks included for installation and cluster lifecycle management.
- Services, via a comprehensive portfolio of common app templates.
Where can I install Kubernetes?
It may be operated practically anywhere on various Linux operating systems (worker nodes can also run on Windows Server). A Kubernetes cluster can span hundreds of bare-metal or virtual servers in a data center, private cloud, or public cloud. It may also be operated on developer workstations, edge servers, microservers such as Raspberry Pis, and ultra-small mobile and IoT devices and appliances.
Kubernetes may even provide a functionally uniform platform across these infrastructures with enough planning (and the correct product and architectural decisions). This implies that apps and settings created and tested on a desktop Kubernetes may be moved with ease to more formal testing, large-scale production, edge, or IoT installations implies that apps and settings created and tested on a desktop Kubernetes may be moved with ease to more formal testing, large-scale production, edge, or IoT installations. In theory, this means that businesses and organizations may create “hybrid” and “multi-clouds” across various platforms, swiftly and affordably fixing capacity issues without lock-in.
What exactly is a Kubernetes cluster?
The K8s architecture is straightforward. You never interface with the nodes that host your application directly; instead, you engage with the control plane, which provides an API and is in charge of scheduling and replicating groups of containers known as pods. Kubectl is a command-line interface that allows you to connect with the API in order to share the desired application state or obtain extensive information about the current status of the infrastructure.
Let’s take a look at the various parts.
Nodes
Each node that hosts a component of your distributed application uses Docker or a comparable container technology, such as CoreOS’ Rocket. In addition, the nodes run two pieces of software: kube-proxy, which provides access to your running app, and kubelet, which accepts commands from the K8s control plane. Flannel, an etcd-backed network fabric for containers, can also be operated on nodes.
Master
The control plane hosts the API server (kube-apiserver), scheduler (kube-scheduler), controller manager (kube-controller-manager), and etcd, a highly available key-value store for shared configuration and service discovery that employs the Raft consensus algorithm.
What exactly does Kubernetes-native infrastructure entail?
The bulk of on-premises Kubernetes installations now run on top of existing virtual infrastructure, with bare metal servers becoming more common. This is a logical progression for data centers. Kubernetes is the containerized application deployment and lifecycle management tool, whereas additional technologies are used to manage infrastructure resources.
But what if you built the datacenter from the ground up to accommodate containers, right down to the infrastructure layer?
You would begin with bare metal servers and software-defined storage, which would be deployed and managed by Kubernetes to provide the infrastructure with the same self-installing, self-scaling, and self-healing capabilities as containers. This is the Kubernetes-native infrastructure concept.







Add Comment